文本处理三剑客之 GREP 一、grep grep:
作用:文本搜索工具,根据指定的“模式”来对需要处理的文本逐行进行检查,打印匹配到的行
模式:由正则表达式及字符构成的搜索条件
格式:grep [OPTION] PATTERN [FILE...]
常见选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 -color=auto 对匹配到的文本进行着色显示,默认 -m -v 显示没有被pattern匹配到的行,即取反 -i 忽略字符大小写 -n 显示匹配的行号 -c 统计匹配到的模式出现的行数 -o 仅显示匹配到的字符串 -q 静默模式,不输出任何信息 -A -B -C -e 实现多个选项间的逻辑or关系,如grep –e 'cat' -e 'dog' file -w 匹配整个单词 -E 使用扩展的正则表达式,相当于egrep -F 不支持正则表达式,相当于fgrep -f file 根据模式文件处理,将一个文件作为模式的条件 -r 递归目录,但不处理软链接 -R 递归目录,处理软链接
范例 (1)取两个文件相同的行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@Rocky8-mini ~] 2 3 4 a [root@Rocky8-mini ~] 1 3 4 5 a [root@Rocky8-mini ~] 3 4 a
(2)分区利用率最大的值
1 2 [root@Rocky8-mini ~] [root@Rocky8-mini ~]
(3)连接当前主机最多的前3个IP及连接数
(4)统计当前连接状态
(5)显示 /etc/profile 文件中非#开头及空白行的内容
1 2 3 [root@Rocky8-mini ~] [root@Rocky8-mini ~] [root@Rocky8-mini ~]
(6)显示IP地址相关信息
(7)算出所有人的年龄总和
1 2 3 4 5 6 7 [root@Rocky8-mini ~] xiaoming:20 xiaohong:18 xiaoqiang:22 [root@Rocky8-mini ~] [root@Rocky8-mini ~] [root@Rocky8-mini ~]
(8)其它选项示例
1 2 3 4 5 6 7 8 9 10 11 [root@Rocky8-mini ~] root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@Rocky8-mini ~] root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@Rocky8-mini ~] sync :x:5:0:sync :/sbin:/bin/syncshutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt
文本处理三剑客之 SED 一、sed 1.1 sed 工作原理 当sed处理某个文件时,首先读取该文件的第一行进入到模式空间中,然后使用sed命令处理该模式空间中的内容,处理完成后,将模式空间中的内容输出到屏幕,接着处理下一行,直至文件末尾。
sed命令默认执行的是p操作,即打印操作,当没有指定特定的操作时,直接将该内容输出至屏幕;如果模式空间中执行了打印操作,那么该行内容就会被打印输出至屏幕,模式空间中的内容默认打印至屏幕,这是该行内容在屏幕上就会出现两次。
1.2 sed基本用法 SYNOPSIS sed [OPTION]... {script-only-if-no-other-script} [input-file]...
常用选项:
1 2 3 4 5 6 -n 不输出模式空间中的内容至屏幕,即不自动打印 -e 多点编辑 -f FILE 从指定的文件中读取编辑脚本 -r,-E 使用扩展的正则表达式 -i.bak 备份文件并原处编辑 -s 将多个文件视为独立文件
script 格式:地址+命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 1. 没有给地址范围,默认对全文做处理 2. 单个地址 $:最后一行 /pattern/:被模式匹配到的每一行 3. 地址范围 /pat1/,/pat2/ 从被pat1模式匹配到的行到被pat2模式匹配到的行 /pat/, 4. 步进 ~ 1~2 奇数行 2~2 偶数行 p 打印当前模式空间中的内容,追加到默认输出之后 Ip 忽略大小写输出 d 删除模式空间中匹配到的行,并读取下一行内容进行处理 a [\]text 在指定行后面追加文本,支持使用\n实现多行追加 i [\]text 在行前面插入文本 c [\]text 替换行为单行或多行文本 w file 保存模式匹配到的行到指定文件 r file 读取指定文件的文本至模式空间中匹配到的行后 = 为模式空间中的行打印行号 ! 模式空间中匹配行取反处理 q 退出sed s/pattern/string/修饰符 分隔符可以是s@@@或s 替换时可用修饰符: g 行内全局替换 p 显示替换成功的行 w /PATH/FILE 将替换成功的行保存至文件中 I,i 忽略大小写
简单示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [root@Rocky8-mini ~] \S Kernel \r on an \m [root@Rocky8-mini ~] \S \S Kernel \r on an \m Kernel \r on an \m [root@Rocky8-mini ~] inet 192.168.119.128 netmask 255.255.255.0 broadcast 192.168.119.255 [root@Rocky8-mini ~] inet 192.168.119.128 netmask 255.255.255.0 broadcast 192.168.119.255 [root@Rocky8-mini ~] saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin [root@Rocky8-mini ~] /dev/sda1 1038336 216624 821712 21% /boot [root@Rocky8-mini ~] 1 2 [root@Rocky8-mini ~] 1 3 4 [root@Rocky8-mini ~] [root@Rocky8-mini ~] 1 2 3 4 5 [root@Rocky8-mini ~] [root@Rocky8-mini ~] 1 4 5 1 2 3 4 5 [root@centos7 ~]
范例 (1)修改网卡名为eth0,并使其生效
1 2 3 [root@centos7 ~] [root@centos7 ~] [root@centos7 ~]
(2)取IP地址
(3)取基名和目录名
1 2 3 4 [root@centos7 ~] [root@centos7 ~]
(4)取文件的前缀和后缀
1 2 3 4 5 6 7 8 9 [root@centos7 ~] anaconda-ks.cfg [root@centos7 ~] [root@centos7 ~] [root@centos7 ~] tar.gz
(5)将非#开头的行加#
1 2 3 [root@centos7 ~] [root@centos7 ~]
(6)取分区利用率
1 2 3 4 5 [root@centos7 ~] /dev/sda1 15 /dev/sdb1 55 /dev/sdc1 56
(7)查看配置文件
1 2 3 4 5 [root@centos7 ~] [root@centos7 ~] [root@centos7 ~]
(8)引用变量
文本处理三剑客之 AWK 一、AWK 1.1 AWK 简介及基本用法 gawk - pattern scanning and processing language
文本处理
输出格式化的文本报表
执行算术运算
执行字符串操作
格式
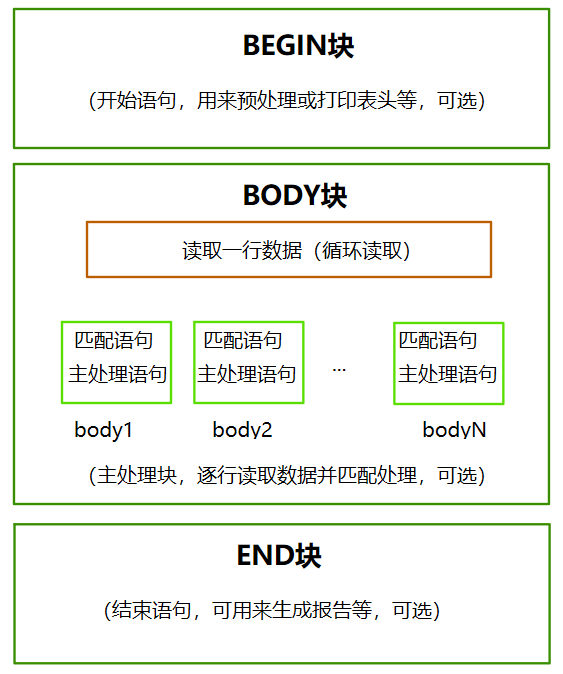
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 awk [options] 'program' var=value file... awk [options] -f programfile var=value file... program 通常放在单引号中,通常由三种部分组成 - BEGIN 语句块 - 模式匹配的通用语句块 - END 语句块 常见选项: - -F"分隔符" 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符 - -v var=value 变量赋值 program 格式: pattern{action statements;...} pattern: 决定动作语句何时触发及触发事件,如:BEGIN、END、正则表达式等 action statements:对数据进行处理,放在{}内指明,常见print 、printf
awk 工作过程
1 2 3 4 5 6 7 1 、通过关键字BEGIN执行BEGIN块的内容,即BEGIN后花括号{}的内容2 、完成BEGIN块的执行,开始执行body块3 、读入有\n换行符分割的记录4 、将每个记录按指定的域分隔符划分域,填充域,$0 表示所有域(即该行所有内容),$1 表示第一个域,$n表示第n个域5 、依次执行各body块,pattern部分表示匹配到该行内容后才会执行awk-command的内容6 、循环读取每一行直至结束,完成body块执行7 、执行END块语句,输出最终结果
分隔符、域和记录
由分隔符将字段分隔形成的各项成为域,标记$1,$2,$3…$n称为域标识,$0为所有域
文件的每一行称为记录
如果省略action,默认执行print $0 的操作
常用的action分类
output statements:print,printf
Expressions:算术,比较表达式等
Compound statements
Control statements
input statements
awk控制语句
{ statements;··· } 组合语句
if 语句
while 语句
do ··· while 语句
for 语句
break、continue、exit
1.2 动作 print 格式:
说明:
逗号分隔符
输出item可以是字符串、数值、当前记录的字段、变量或awk的表达式
如果省略item,则默认print $0
固定字符使用“ ”引起来,变量和字符不需要
示例:
1 2 3 4 5 [root@centos7 ~] hello,awk! [root@centos7 ~] [root@centos7 ~]
Example1:取出网站访问量最大的前3个IP
1 2 3 4 5 6 7 8 9 10 [root@centos7 ~] 58.87.87.99 - - [27/Apr/2020:03:10:51 +0800] "POST /wp-cron.php?doing_wp_cron=1587928251.0032949447631835937500 HTTP/1.1" "" sendfileon 61.131.3.225 - - [27/Apr/2020:03:10:51 +0800] "GET / HTTP/1.1" "" sendfileon 157.245.106.153 - - [27/Apr/2020:03:10:52 +0800] "GET /wp-login.php HTTP/1.1" "" sendfileon 157.245.106.153 - - [27/Apr/2020:03:10:53 +0800] "POST /wp-login.php HTTP/1.1" "" sendfileon 157.245.106.153 - - [27/Apr/2020:03:10:54 +0800] "POST /xmlrpc.php HTTP/1.1" "" sendfileon [root@centos7 ~] 5498 122.51.38.20 2161 117.157.173.214 953 211.159.177.120
Example2:取出分区利用率
1 2 3 4 5 6 7 8 9 10 [root@centos7 ~] /dev/sdc1 56 /dev/sdb1 55 /dev/sda1 15 [root@centos7 ~] /dev/sdc1 56 /dev/sdb1 55 /dev/sda1 15
Example3:取Nginx的访问日志中的IP和时间
1 2 3 4 [root@centos7 ~] 58.87.87.99 27/Apr/2020:03:10:51 61.131.3.225 27/Apr/2020:03:10:51 157.245.106.153 27/Apr/2020:03:10:52
Example4:取 ifconfig 输出结果中的地址
1 2 3 4 [root@centos7 ~] 192.168.119.165 [root@centos7 ~] 192.168.119.165
Example5:参考主机文件host.log格式,提取“.wuhaolam.top”前面主机名部分并写入到该文件中
1 2 3 4 5 6 7 8 9 10 11 12 [root@centos7 ~] 1 www.wuhaolam.top 2 blog.wuhaolam.top 3 study.wuhaolam.top [root@centos7 ~] [root@centos7 ~] 1 www.wuhaolam.top 2 blog.wuhaolam.top 3 study.wuhaolam.top www blog study
1.3 awk 变量 1.3.1 awk常见的内置变量
FS:输入字段分隔符,默认为空白字符,相当于 -F
1 2 3 4 5 6 7 8 9 [root@centos7 ~] root : 0 bin : 1 daemon : 2 [root@centos7 ~] root:0 bin:1 daemon:2
1 2 3 4 [root@centos7 ~] root 0 /bin/bash [root@centos7 ~] root:0:/bin/bash
RS:输入记录record分隔符,以指定的符号作为一个新纪录的分割符
1 2 3 4 5 6 7 8 [root@centos7 ~] polkitd:x:999:998:User for polkitd:/:/sbin/nologin [root@centos7 ~] polkitd:x:999:998:User for polkitd:/:/sbin/nologin [root@centos7 ~]
ORS:输出记录分隔符,输出时用指定符号代替换行符
1 2 3 [root@centos7 ~] polkitd:x:999:998:User for polkitd:/:/sbin/nologin [root@centos7 ~]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@centos7 ~] 0 1 1 3 1 1 1 1 1 1 1 1 1
Example1:连接数最多的前三个IP
1 2 3 4 5 6 7 8 9 10 11 12 [root@centos7 ~] State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 0 123.57.218.140:80 210.21.36.228:17036 ESTAB 0 0 127.0.0.1:55388 127.0.0.1:27017 ESTAB 0 0 123.57.218.140:22 101.200.188.230:42002 ESTAB 0 96 123.57.218.140:22 61.149.193.234:50314 ··· [root@centos7 ~] 44 127.0.0.1 10 113.234.28.244 8 124.64.18.135 [root@centos7 ~]
Example2:将连接数超过100个以上的IP放入黑名单拒绝访问
1 2 3 4 5 6 7 8 9 [root@centos7 ~] LINK=100 while true ;do ss -nt | awk -F' +|:' '/^ESTAB/{print $(NF-2)}' | sort | uniq -c | while read count ip;do if [ $count -gt $LINK ];then iptables -A INPUT -s $ip -j REJECT fi done done
1 2 3 4 [root@centos7 ~] 21 [root@centos7 ~] 0
Example1:显示awk处理文本时的记录及每条记录对应的内容
1 2 3 4 5 [root@centos7 ~] 1 \S 2 Kernel \r on an \m 3 4 CentOS Linux release 7.9.2009 (Core)
Example2:取IP地址
1 2 [root@centos7 ~] [root@centos7 ~]
1 2 3 4 5 6 7 8 9 10 [root@centos7 ~] 1 \S 2 Kernel \r on an \m 3 4 CentOS Linux release 7.9.2009 (Core) [root@centos7 ~] 1 \S 2 Kernel \r on an \m 3 1 CentOS Linux release 7.9.2009 (Core)
ARGV:数组,保存的是命令行所给的各参数,ARGV[0],····
1 2 3 4 [root@centos7 ~] awk /etc/issue /etc/redhat-release
1.3.2 自定义变量 自定义变量区分大小写,有如下两种定义方式:
-v var=value
在program中直接定义
1 2 3 4 5 6 7 [root@centos7 ~] test2=hello [root@centos7 ~] hello hello 注:若两种方式同时使用,在program中定义的变量优先级更高
1.4 printf 动作 printf 可以实现格式化输出
1 2 3 4 5 6 printf "FORMAT" , item1, item2, ...说明: - 必须指定FORMAT - 不会自动换行,需要显示给出换行控制符\n - FORMAT 中需要分别为后面每个item指定格式符
格式符:与 item 对应
1 2 3 4 5 6 7 8 %s: 显示字符串 %d, %i: 显示十进制整数 %f: 显示为浮点数 %e, %E: 显示科学计数法数值 %c: 显示字符的ASCII码 %g, %G: 以科学计数法或浮点数显示数值 %u: 无符号整数 %%: 显示百分号本身
修饰符
1 2 3 - 左对齐(默认右对齐),如 %-15s + 显示数值的正负符号,如 %+d
示例
1 2 3 4 5 6 7 8 awk -F: '{printf "%s\n",$1}' /etc/passwd awk -F: '{printf "%20s\n",$1}' /etc/passwd awk -F: '{printf "%-20s\n",$1}' /etc/passwd | cat -A awk -F: '{printf "%-20s %d\n",$1,$3}' /etc/passwd awk -F: '{printf "Username: %-20s UID: %d\n",$1,$3}' /etc/passwd
1.5 操作符 算数操作符
1 2 3 x+y, x-y, x*y, x/y, x^y, x%y -x 取负数 +x 将字符串转换为数值
字符串操作符:没有符号的操作符,字符串连接
赋值操作符
1 =, +=, -=, *=, /=, %=, ^=,++, --
示例
比较操作符
示例
1 2 3 4 5 6 [root@wh-aliyun ~] Kernel \r on an \m [root@wh-aliyun ~] nobody:x:65534:65534:Kernel Overflow User:/:/sbin/nologin wh:x:1000:1000::/home/wh:/bin/bash
示例:取奇数行和偶数行
1 2 3 4 5 6 7 8 9 10 11 12 [root@wh-aliyun ~] 1 3 5 7 9 [root@wh-aliyun ~] 2 4 6 8 10
模式匹配符
1 2 ~ 左边是否和右边匹配,包含关系 !~ 是否不匹配
示例
1 2 3 4 5 6 7 8 9 [root@wh-aliyun ~] root:x:0:0:root:/root:/bin/bash [root@wh-aliyun ~] root [root@wh-aliyun ~] 9 [root@wh-aliyun ~] 172.22.21.46
逻辑操作符
示例
1 2 3 4 5 [root@wh-aliyun ~] 0 [root@wh-aliyun ~] [root@wh-aliyun ~] [root@wh-aliyun ~]
条件表达式(三目表达式)
1 2 selector?if-true-expression:if-false-express
示例
1 2 3 4 awk -F: '{$3>=1000?usertype="common user":usertype="system user";printf "%-20s:%12s\n",$1,usertype}' /etc/passwd [root@wh-aliyun ~] 9 OK
1.6 模式 PATTERN PATTERN:根据PATTERN条件,过滤匹配的行,再做处理
1 awk -F: '{print $1,$3}' /etc/passwd
/regular expression/:仅处理模式匹配到的行,需要用/ /括起来
1 2 3 4 5 [root@centos7 ~]# df -Th | awk '/^\\/dev\\/sd/{print $1,$6}' /dev/sda3 5% /dev/sdb1 4% /dev/sda2 11% /dev/sda1 3%
1 2 3 4 5 6 7 8 9 10 11 12 [root@centos7 ~]# seq 3 | awk '' [root@centos7 ~]# seq 3 | awk '1' 1 2 3 [root@centos7 ~]# seq 3 | awk 'abc' [root@centos7 ~]# seq 3 | awk -v abc=0 'abc' [root@centos7 ~]# seq 3 | awk -v abc="aa" 'abc' 1 2 3
示例:
1 2 3 4 5 6 [root@centos7 ~]# awk -v FS=':' '$NF=="/bin/bash"{print $1FS$NF}' /etc/passwd root:/bin/bash ftpuser:/bin/bash [root@centos7 ~]# awk -v FS=':' '$NF ~ "/bin/bash"{print $1FS$NF}' /etc/passwd root:/bin/bash ftpuser:/bin/bash
不支持直接用行号,但可以使用变量NR间接指定行号 /pat1/,/pat2/ 不支持直接给出数字格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@centos7 ~]# seq 7 | awk 'NR>=3 && NR<6' 3 4 5 [root@centos7 ~]# awk 'NR>3 && NR<6{print NR,$0}' /etc/passwd 4 adm:x:3:4:adm:/var/adm:/sbin/nologin 5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@centos7 ~]# awk '/^bin/,/^adm/' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin [root@centos7 ~]# sed -n '/^bin/,/^adm/p' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次
1 [root@centos7 ~]# awk -F: 'BEGIN {print "--------------"}NR>3 && NR<6{print $1,$3,$NF}END{print "------------"}' /etc/passwd
1.7 条件判断 if-else 语法:
1 2 if(condition){statement; ......} [else statement] if(condition1){statement1} else if (condition2){statement2} else if (condition3) {statements} ...... else {statementN}
使用场景:对 awk 取得的整行或某个字段做条件判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 1、UID 大于 1000 [root@centos7 ~]# awk -F: '{if($3>=1000)print $1,$3}' /etc/passwd 2、小于3,打印a; 小于5,打印b; 其它打印c [root@centos7 ~]# seq 7 | awk '{if($1<3){print "a"} else if($1<5){print "b"} else {print "c"}}' a a b b c c c 3、磁盘使用率大于10%就打印出该文件系统的设备名称和使用率 [root@centos7 ~]# df -Th | awk -F"[ %]+" '/\\/dev\\/sd/{if($6>10){print $1,$6}}' /dev/sda2 11
1.8 条件判断 switch 语法:
1 switch(expression) {case VALUE1 or /REGEXP/: statement1; case VALUE2 or /REGEXP2/: statement2; ...; default: statementN}
1.9 循环 while 语法:
1 2 3 4 5 6 while (condition) {statement; ......} 条件为“真”,进入循环;条件为“假”,退出循环 使用场景: 对一行内的多个字段逐一类似处理时使用 对数组中的各元素逐一处理时使用
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 [root@centos7 ~]# awk -v i=1 -v sum=0 'BEGIN{while(i<=100) {sum=sum+i;i++}; print sum}' 5050 # 内置函数length()返回字符数,而非字节数 [root@centos7 ~]# awk 'BEGIN{print length("hello")}' 5 [root@centos7 ~]# awk 'BEGIN{print length("中国")}' 2 [root@centos7-mini3 ~]# awk '/^[[:space:]]*linux16/{i=1; while(i<=NF) {print $i,length($i); i++}}' /etc/grub2.cfg linux16 7 /vmlinuz-3.10.0-1160.el7.x86_64 31 root=/dev/mapper/centos-root 28 ro 2 crashkernel=auto 16 rd.lvm.lv=centos/root 21 rd.lvm.lv=centos/swap 21 rhgb 4 quiet 5 net.ifnames=0 13 linux16 7 /vmlinuz-0-rescue-b4f1e030bb9b4be0b3ac55e533a88806 50 root=/dev/mapper/centos-root 28 ro 2 crashkernel=auto 16 rd.lvm.lv=centos/root 21 rd.lvm.lv=centos/swap 21 rhgb 4 quiet 5 net.ifnames=0 13 [root@centos7-mini3 ~]# awk '/^[[:space:]]*linux16/{i=1; while(i<=NF) {if(length($i)>20) {print $i,length($i)} i++}}' /etc/grub2.cfg /vmlinuz-3.10.0-1160.el7.x86_64 31 root=/dev/mapper/centos-root 28 rd.lvm.lv=centos/root 21 rd.lvm.lv=centos/swap 21 /vmlinuz-0-rescue-b4f1e030bb9b4be0b3ac55e533a88806 50 root=/dev/mapper/centos-root 28 rd.lvm.lv=centos/root 21 rd.lvm.lv=centos/swap 21
1.10 循环 do-while 语法:
1 do {statement; ...} while(condition)
意义:无论真假,至少执行一次循环体
1 2 [root@centos7 ~]# awk 'BEGIN{ total=0;i=1;do{ total=total+i;i++; } while(i<=100);print total }' 5050
1.11 循环 for 语法:
1 2 3 4 5 6 7 for(expr1;expr2;expr3) {statement;...} 常见用法: for(variable assignment;condition;iteration process) {for-body} 特殊用法:可遍历数组中的元素 for(var in array) {for-body}
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@centos7-mini3 ~]# awk 'BEGIN{sum=0; for(i=1;i<=100;i++) {sum=sum+i} print sum}' 5050 [root@centos7-mini3 ~]# awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {if (length($i)>30) {print $i,length($i)}}}' /etc/grub2.cfg /vmlinuz-3.10.0-1160.el7.x86_64 31 /vmlinuz-0-rescue-b4f1e030bb9b4be0b3ac55e533a88806 50 [root@centos7-mini3 ~]# time (awk 'BEGIN{ total=0; for(i=0;i<=100000;i++) {total=total+i;} print total;}') 5000050000 real 0m0.012s user 0m0.000s sys 0m0.012s [root@centos7-mini3 ~]# time ( total=0; for i in {1..100000}; do total=$(($total+$i)); done; echo $total ) 5000050000 real 0m0.310s user 0m0.301s sys 0m0.010s [root@centos7-mini3 ~]# time (for ((i=0;i<=100000;i++));do let total=$total+$i; done; echo $total) 5000050000 real 0m0.629s user 0m0.575s sys 0m0.054s [root@centos7-mini3 ~]# time (seq -s "+" 100000 | bc) 5000050000 real 0m0.040s user 0m0.007s sys 0m0.034s [root@centos7-mini3 ~]# echo '1*d3(#*(^y43' | awk -F "" '{ for(i=1;i<=NF;i++) {if ( $i ~ /[0-9]/ ) {str=(str $i)}} print str}' 1343
1.12 continue 和 break 语法:
1 2 3 4 5 continue 中断本次循环 continue [n] break 中断整个循环 break [n]
示例
1 2 3 4 [root@centos7-mini3 ~]# awk 'BEGIN{sum=0; for (i=1;i<=100;i++) {if (i==50) continue; sum=sum+i} print sum}' 5000 [root@centos7-mini3 ~]# awk 'BEGIN{sum=0; for (i=1;i<=100;i++) {if (i==50) break; sum=sum+i} print sum}' 1225
1.13 next next 可以提前结束对本行的处理而直接进入下一行处理(awk 自身循环)
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 此循环为 awk 的自身循环,不能使用 continue 语句 [root@centos7-mini3 ~]# awk -F: '{if($3%2!=0) continue; print $1,$3}' /etc/passwd awk: cmd. line:1: error: `continue' is not allowed outside a loop [root@centos7-mini3 ~]# awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd root 0 daemon 2 lp 4 shutdown 6 mail 8 games 12 ftp 14 systemd-network 192 sshd 74 geoclue 998
1.14 数组 语法:
1 2 3 4 5 6 7 8 9 10 awk 的数组为关联数组 array_name[index-expression] weekdays["mon"]="Monday" index-expression - 利用数组,实现 key/value 功能 - 可使用任意字符串;字符串要使用双引号括起来 - 如果某数组元素事先不存在,在引用时,awk 会自动创建此元素,并将其值初始化为“空串” - 若要判断数组中是否存在某元素,要使用“index in array”格式进行遍历
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@centos7-mini3 ~]# awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";weekdays["wed"]="wednesday";print weekdays["tue"]}' Tuesday [root@centos7-mini3 ~]# awk '!line[$0]++' /etc/issue \S Kernel \r on an \m [root@centos7-mini3 ~]# awk '{print !line[$0]++, $0, line[$0]}' /etc/issue 1 \S 1 1 Kernel \r on an \m 1 1 1 [root@centos7-mini3 ~]# awk '{print !line[$0]++;print $0, line[$0]}' /etc/issue 1 \S 1 1 Kernel \r on an \m 1 1 1
示例:判断索引是否存在
1 2 3 4 [root@centos7-mini3 ~]# awk 'BEGIN{array["i"]="x";array["j"]="y";if ("i" in array) {print "存在,值为:",array["i"]} else {print "不存在"}}' 存在,值为: x [root@centos7-mini3 ~]# awk 'BEGIN{array["i"]="x";array["j"]="y";if ("abc" in array) {print "存在,值为:",array["abc"]} else {print "不存在"}}' 不存在
如果要遍历数组中的每一个元素,要使用 for 循环
1 2 3 for(var in array) {for-body} note: var 会遍历 array 的每个索引
示例
1 2 3 4 5 6 7 8 9 10 [root@centos7 ~]# awk 'BEGIN{stu["1st"]="zhao";stu["2nd"]="qian";stu["3rd"]="sun";for(x in stu){print x":"stu[x]}}' 3rd:sun 2nd:qian 1st:zhao # 显示主机连接状态出现的次数 [root@centos7 ~]# ss -nta | awk 'NR!=1{print $1}' | sort | uniq -c 25 ESTAB 14 LISTEN 50 TIME-WAIT
1.15 AWK 函数 AWK 的函数分为内置和自定义函数
官方文档:https://www.gnu.org/software/gawk/manual/gawk.html#Functions
1.15.1 常见的内置函数
1 2 3 rand(): 返回 0 和 1 之间的一个随机数 srand(): 配合 rand() 函数,生成随机数的种子 int(): 返回整数
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@centos7 ~] 0.518181 [root@centos7 ~] 0.39578 [root@centos7 ~] 0.471864 [root@centos7 ~] 86 99 2 65 52
1 2 3 4 length([s]): 返回指定字符串的长度 sub(r,s,[t]): 对t字符串搜索,r表示模式匹配的内容,并将第一个匹配内容替换为s gsub(r,s,[t]): 对t字符串进行搜索,r表示的模式匹配的内容,并全部替换为s所表示的内容 split (s,array,[r]): 以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第一个索引值为1,第二个索引值为2,.....
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@centos7 ~] [root@centos7 ~] 8888-08:08 08:08:08 [root@centos7 ~] 8888-08:08 08:08:08 [root@centos7 ~] 8888-08-08 08-08-08 [root@centos7 ~] 10.243.20.50 2 10.243.20.51 71 10.243.10.10 1
空格是awk中的字符串连接符,如果system中需要使用awk中的变量可以使用空格分离,除了awk的变量外其它一律用””引用起来
1 2 3 4 [root@centos7 ~] centos7 [root@centos7 ~] your score is 100
官方文档:https://www.gnu.org/software/gawk/manual/gawk.html#Time-Functions
1 2 systime() 当前时间到1970年1月1日的秒数 strftime() 指定时间格式
示例
1 2 3 4 5 [root@Rocky8-mini3 ~] 1699323534 [root@Rocky8-mini3 ~] 2023-11-06T20:20
1.15.2 自定义函数 自定义函数格式:
1 2 3 4 function name (parameter,parameter,...) { statements return expression }
示例
1 2 3 4 5 6 7 8 9 [root@Rocky8-mini3 ~] function sum (x,y) { result=x+y return result } BEGIN {print sum (a,b)} [root@Rocky8-mini3 ~] 50